Используем Phinx - систему миграций баз данных
2018-02-17 12:00:00
Современное программирование невозможно представить без системы контроля версий. Система контроля версий - это специальное ПО, позволяющее команде программистам с удобством разрабатывать общий проект. Она храни историю версий всех файлов и позволяет в удобном виде решать конфликты между в коде, если в один из его участков вносили изменения сразу несколько программистов. Но как быть, если изменения касались не кода, а структуры БД. Как команде программистов актуализировать у себя на локале актуальную версию базы данных? Для этого и придумали систему миграций баз данных.
Почему Phinx?
Практически в каждом современном PHP фреймворке есть своя система миграций. Но когда работаешь с разными фреймворками, то хочется привести всё к общему знаменателю и использовать единую для всех систему миграций. Я выбрал Phinx по следующем причинам:
- Phinx не привязан к определённому фреймворку и может работать как самостоятельный компонент
- В данной системе миграций есть разделения на миграцию структуры и на миграцию данных (Seeder).
- Поддержкой и обновлением Phinx на сегодняшний день занимаются разработчики популярного фреймворка - CakePHP
Как установить phinx
Для установки актуальной версии phinx необходимы:
- PHP 5.6 или выше
- php-cli, чтобы выполнять PHP скрипты из консоли
- Composer - менеджер зависимостей для PHP
- MySQL или Postgress база данных, на которую будут накатываться миграции
Приступаем к установке.
Установка через composer и инициализация phinx
Откройте консоль, перейдите в папку своего проекта и выполните команду:
composer require robmorgan/phinx
После чего в рабочей папке должен появиться файл composer.json (если его до этого не было) с примерно следующим содержимым:
"require": {
"robmorgan/phinx": "^0.8.1"
}
Теперь выполняем команду:
composer update
После чего в корне проекта появится папка vendor с множеством подпапок. Пакет phinx установлен. Теперь инициализируем конфиг, выполнив команду:
php vendor/bin/phinx init
В корне сайта должен появится файл с конфигом phinx.yml, где мы и будем задавать необходимые настройки для phinx.
Настройка phinx и рабочей среды
Создадим в корне проекта папки:
database/migrations/ - здесь будут храниться наши маграции
database/seed/ - здесь будут наши Seed-ы данных
database/data/ - сюда будем складывать sql файлы (в случае объёмных запросов, мы будем выносить их в sql файлы, которые будем подтягивать из файлов миграций)
Открываем файл phinx.yaml и прописываем в пути к созданным папкам:
paths:
migrations: %%PHINX_CONFIG_DIR%%/database/migrations
seeds: %%PHINX_CONFIG_DIR%%/database/seeds
Далее заполняем данные для подключения к БД. Phinx поддерживает работу с окружениями. Для каждого окружения можно выбрать отдельную базу. Заполните данные для подключения к базе данных хотя бы для одного окружения.
environments:
default_migration_table: phinxlog
default_database: development
production:
adapter: mysql
host: localhost
name: your_db
user: your_username
pass: your_password
port: 3306
charset: utf8
Работа с миграциями Phinx
Теперь, когда мы всё установили и настроили, можем приступить к созданию миграций. Phinx позволяет:
1) Создавать миграции
2) Применять миграции
3) Откатывать миграции
4) Создавать Seed-ы данных и выполнять их
5) Создавать брейкпоинты
А теперь обо всём по порядку.
Создание миграций Phinx
Для создания миграций phinx выполните команду из корня проекта:
vendor/bin/phinx create MyMigration
После выполнения команды должен появиться файл типа:
database/migrations/20180217071103_my_migration.php
Внутри файла будет класс миграции с методом change.
Давайте разберёмся с методами, которые можно использовать в классе миграции.
Метод up()
В этом методе выполняется выполняется код накатывания миграций. При этом можно использовать как голый язык SQL, так и Query Builder phinx-а. Приведу пример миграции - создание таблицы users.
<?php
use Phinx\Migration\AbstractMigration;
class MyMigration extends AbstractMigration
{
public function up()
{
$sql = '
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`login` varchar(255) NOT NULL,
`email` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `user`
ADD PRIMARY KEY (`id`);
ALTER TABLE `user`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;';
$this->execute($sql);
}
}
Переменной $sql мы присвоили строку, которая представляет собой несколько SQL запросов: создание таблицы, добавление первичного ключа, назначение автоинкремента. Далее мы выполнили метод execute, передав в него в качестве аргумента нашу переменную. При выполнении миграции этот метод исполнит запрос. Выполним миграцию, чтобы убедится в этом.
Наберём в консоли:
php vendor/bin/phinx migrate
И увидим следующее:
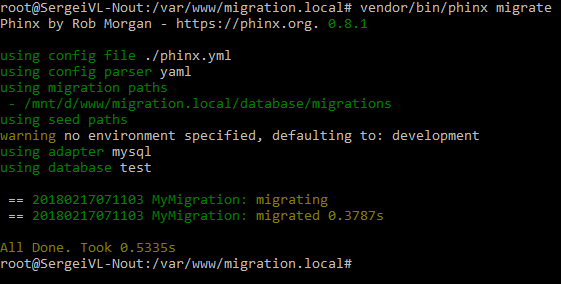
Миграция успешно выполнилась и в базе данных создалась таблица users. А теперь разберёмся как откатывать (отменять) миграции. Данная команда выполняет все миграции, которые ещё не были выполнены. Выполняются они в порядке их создания. Информация о выполненных миграциях записывается в таблицу phinxlog. По записям в ней система phinx и определяет, какие из миграций уже были применены.
Метод down()
Для отката миграций предназначен метод down(). В нём вы пишите, так сказать, противоположный предыдущему запрос. Добавим отмену миграций в тот же класс. Если в первом методе мы создаём таблицу, в текущем мы должны её удалять:
<?php
use Phinx\Migration\AbstractMigration;
class MyMigration extends AbstractMigration
{
// ...
public function down()
{
$sql = 'DROP TABLE `user`';
$this->execute($sql);
}
}
Для выполнения отката миграций выполняем в консоли:
vendor/bin/phinx rollback
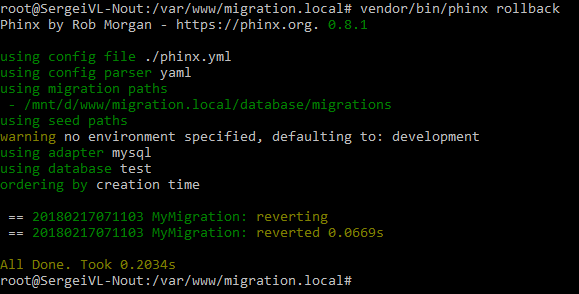
Миграция откатилась. Таблица user исчезла из нашей базы. Следует помнить, что за одну команду откатывается только одна миграция. Если нужно откатить две - выполните команду два раза. А если мы выполним команду `vendor/bin/phinx migrate`, то таблица появится снова! Рекомендую прописывать как логику накатывания миграций в методе up(), так и логику отмены миграций в методе down(). Эти возможности очень выручают в процессе разработке веб приложений.
Метод change()
Для упрощения написания миграций, разработчики внедрили метод change(), который включает в себя логику как применения, так и откатывания миграций. Данный метод используется вместо up() и down(). Вы пишите запрос только на создание, а система phinx уже сама выполняет обратную логику при откате миграции.
Однако, запросы в методе change() обязательно должны быть написаны через Query Buider пакета phinx.
<?php
use Phinx\Migration\AbstractMigration;
class MyMigration extends AbstractMigration
{
public function change()
{
$table = $this->table('user');
$table->addColumn('login', 'string', ['limit' => 255])
->addColumn('email', 'string', ['limit' => 255])
->addColumn('password', 'string', ['limit' => 255])
->create();
}
}
Этот метод по действию абсолютно идентичен up() и down(), которые мы писали ранее. Вы могли заметить, что в коде нет создания столбца id и назначения его первичным ключом с автоинкрементом. При использовании метода change() первичный ключ id создаётся автоматически. Мы также не прописывали NOT NULL, потому что эта опция назначается столбцам phinx-ом по умолчанию.
Использование breakpoint
Для того, чтобы не откатить лишнего, в phinx предусмотрен механизм breakpoint. Если вы уверены, что начиная с какой-то миграции откатываться точно не придётся, можете назначить на неё breakpoint с помощью команды:
phinx breakpoint -t 20180217071103
Где параметр t - время выполнение нашей миграции. Если вы посмотрите на файлы миграций, то увидите, что у каждого файла в префиксе цифры, обозначающие дату+время создания файла миграции. При установке брейкпоинта на определённую миграцию, phinx, дойдя до неё, будет блокировать попытки отката.
Посев данных в phinx
Если нам требуется наполнить таблицу какими либо данными, мы можем использовать специальный механизм phinx под названием Seeding (или посев данных). Для создания Seed-а выполните команду:
php vendor/bin/phinx seed:create UserSeeder
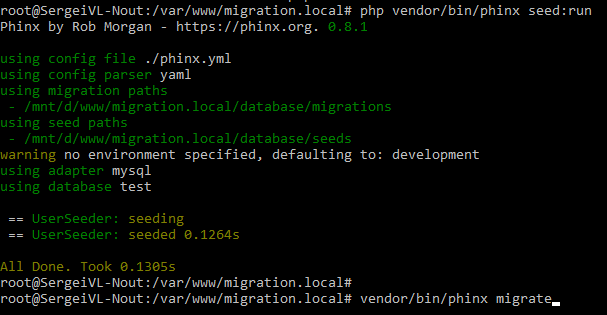
После выполнения команды появится файл database/seeds/UserSeeder.php с методом run(). Для добавления данных в таблицу user посетим в файл следующий код:
<?php
use Phinx\Seed\AbstractSeed;
class UserSeeder extends AbstractSeed
{
public function run()
{
$data = [
[
'login' => 'sergei',
'email' => 'sergei@test.ru',
'password' => 'fGhvs4Fgj',
],
[
'login' => 'ivan',
'email' => 'ivan@test.ru',
'password' => 'gHdc57jFsaw',
],
[
'login' => 'ivan',
'email' => 'ivan@test.ru',
'password' => 'jlS56nH',
]
];
$user = $this->table('user');
$user->insert($data)->save();
}
}
Чтобы осуществить посев данных, выполните команду:
php vendor/bin/phinx seed:run -s UserSeeder
Если ваша таблица заполнилась данными, значит вы всё сделали правильно.
Рецепты по работе с Phinx
При работе с миграциями возникают разные случаи, требующие внедрения дополнительной логики. Я опишу приёмы, которые использую при разработке веб приложений.
Выполнение миграций только для определённого окружения
Недавно я прикручивал миграции к уже существующему проекту. Его база была уже наполнена. И мне потребовалось сделать так, чтоб на моём локальном сервере миграции, которые создают базовые таблицы выполнялись, а на боевом - нет (так как таблицы там уже существуют). Тогда мне пришло в голову решение - выполнять запросы в миграциях в зависимости от текущего окружения. Для окружения production запрос на создание таблицы выполнятся не должен.
<?php
use Phinx\Migration\AbstractMigration;
class MyMigration extends AbstractMigration
{
public function change()
{
$environment = $this->input->getParameterOption('-e');
if ($environment !== 'production') {
$table = $this->table('user');
$table->addColumn('login', 'string', ['limit' => 255])
->addColumn('email', 'string', ['limit' => 255])
->addColumn('password', 'string', ['limit' => 255])
->create();
}
}
}
Таким образом, передавая параметр окружения к команде, можно реализовать логику условия выполнения миграций:
vendor/bin/phinx migrate -e development
vendor/bin/phinx migrate -e production
При исполнении первой команды запрос выполнится, при второй - нет.
Накатывание дампа / выполнение запросов из файла *.sql
Идея миграций в том, чтобы развернуть проект на любом сервере одной командой. Поэтому если вы внедряете миграции на уже работающий проект, то вам желательно создать так называемую InitSchema миграцию, которая создаст основным таблицы единым запросом. Но, как правило размер такого запроса настолько огромен, что нецелесообразно помещать его в сам класс миграция.
Я рекомендую выносить его в отельный файл с расширением sql. Сперва создадим новую миграцию, выполнив команду:
vendor/bin/phinx create InitSchemaMigration
Затем создадим файл:
database/data/initSchema.sql
Наполним его различными запросами. Можете сделать дамп структуры какого-то из ваших проектов и сохранить запросы из него в этот файл.
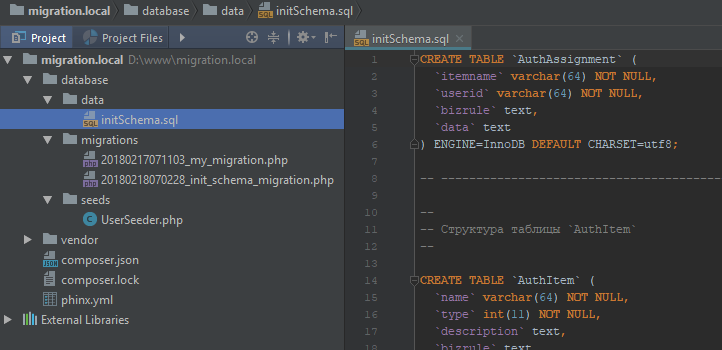
Затем, переходим в созданный класс миграции и подгружаем из файла initSchema.sql наши запросы.
<?php
use Phinx\Migration\AbstractMigration;
class InitSchemaMigration extends AbstractMigration
{
public function up()
{
$sql = file_get_contents('database/data/initSchema.sql', true);
$this->query($sql);
}
public function down()
{
$sql = '
SET foreign_key_checks = 0;
DROP TABLE `AuthAssignment`, `AuthItem`, `AuthItemChild`;
SET foreign_key_checks = 1;';
$this->execute($sql);
}
}
Содержимое файла подгрузили функцией file_get_contents(). Но для метода отката миграции (если он вам нужен в данном случае) придётся перечислять все таблицы в команде на DROP TABLE. Кроме того, пришлось отключить проверку внешних ключей перед выполнение запроса.
Отключение проверки внешних ключей в методе отката миграций
При удалении таблиц, MySQL проверяем наличие внешних ключей. И если они присутствуют, команда DROP не выполнится. Поэтому, перед запросом, временно отключаем проверку внешних ключей командой
SET foreign_key_checks = 0;
После чего, снова включаем ещё, чтобы наш сервер БД работал в штатном режиме:
SET foreign_key_checks = 1;
Выполнение phinx миграций в цикле
Часто возникают случае, когда удобней работать не с одной переменной, в которой содержатся SQL запросы, а с массивом. В таком случае я рекомендую формировать массив запросов и выполнять их в цикле:
public function up()
{
$sqlQueries = [];
$sqlQueries[] = "INSERT INTO `tbl_lookup` (`name`, `code`, `type`, `position`) VALUES
('Доверенность на получение', 1, 'DocType', 1);";
$sqlQueries[] = "INSERT INTO `tbl_lookup` (`name`, `code`, `type`, `position`) VALUES
('Доверенность на представителя', 2, 'DocType', 2);";
$sqlQueries[] = "INSERT INTO `tbl_lookup` (`name`, `code`, `type`, `position`) VALUES
('Присоединение к регламенту', 3, 'DocType', 3);";
$sqlQueries[] = "INSERT INTO `tbl_lookup` (`name`, `code`, `type`, `position`) VALUES
('Заявление на экспорт', 4, 'DocType', 4);";
$sqlQueries[] = "INSERT INTO `tbl_lookup` (`name`, `code`, `type`, `position`) VALUES
('Заявление на изготовление', 5, 'DocType', 5);";
foreach ($sqlQueries as $sql) {
$this->execute($sql);
}
}